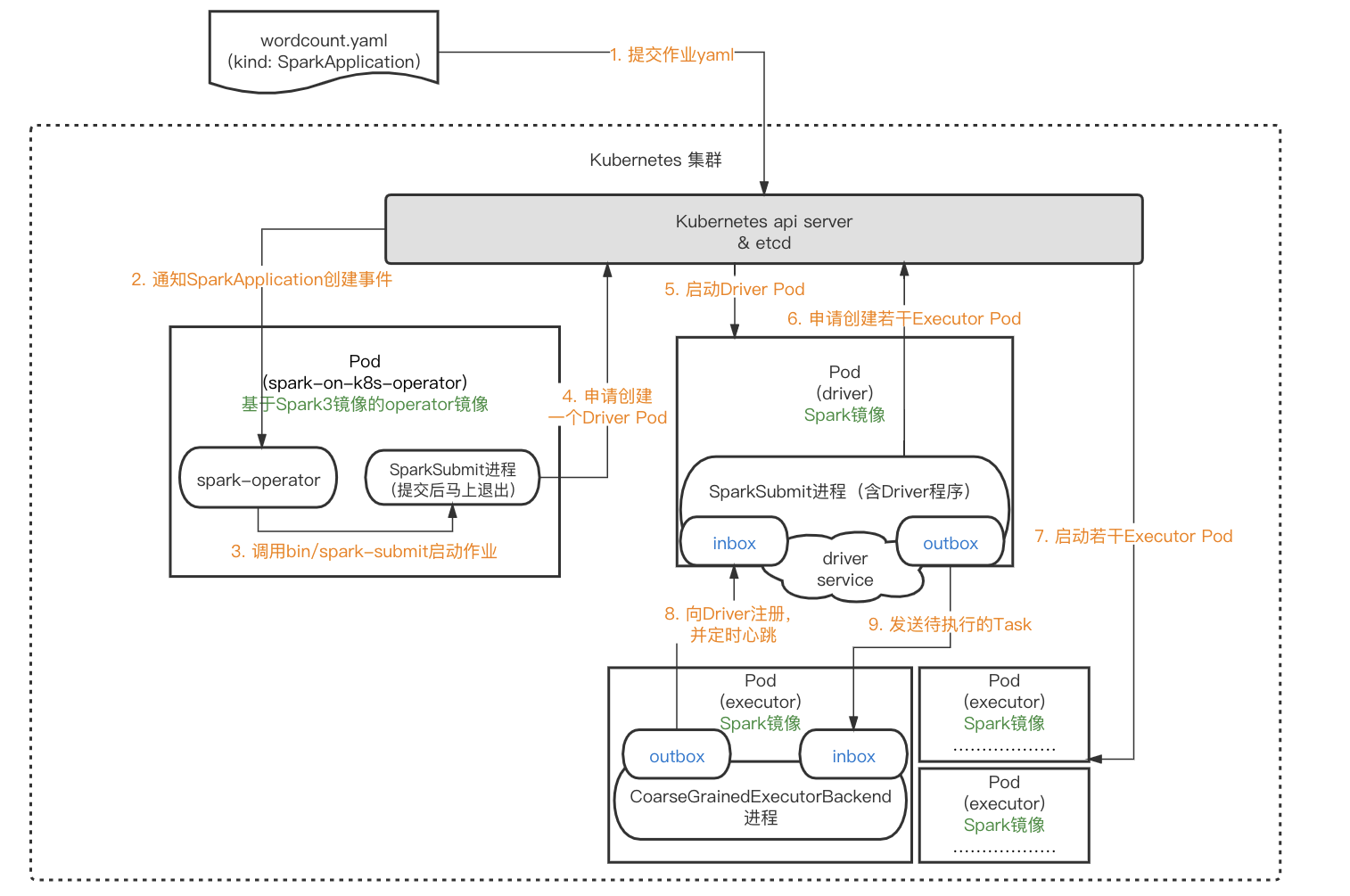
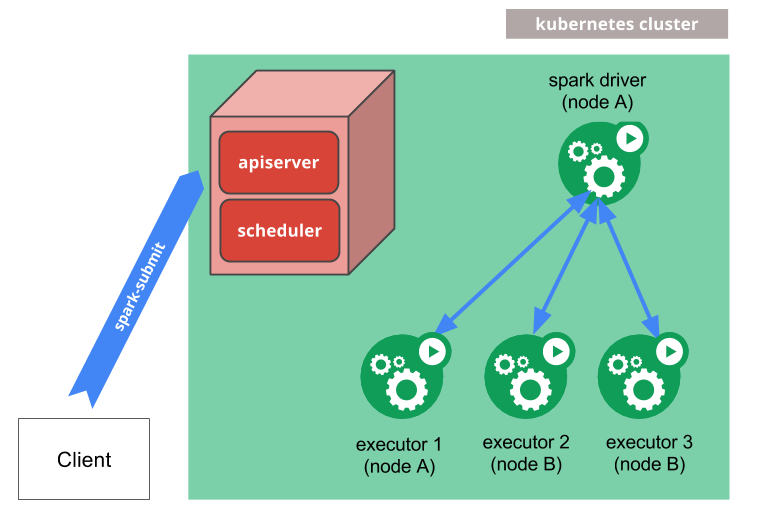
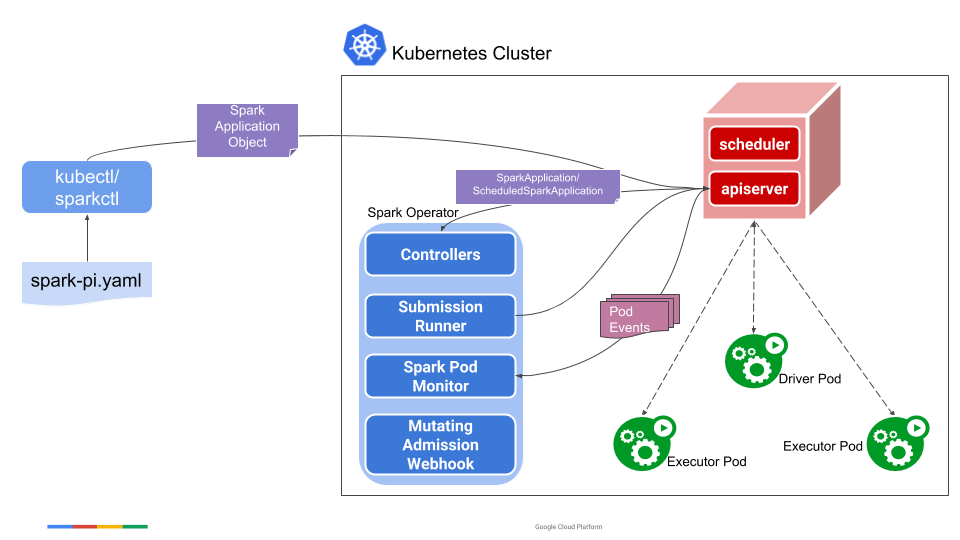
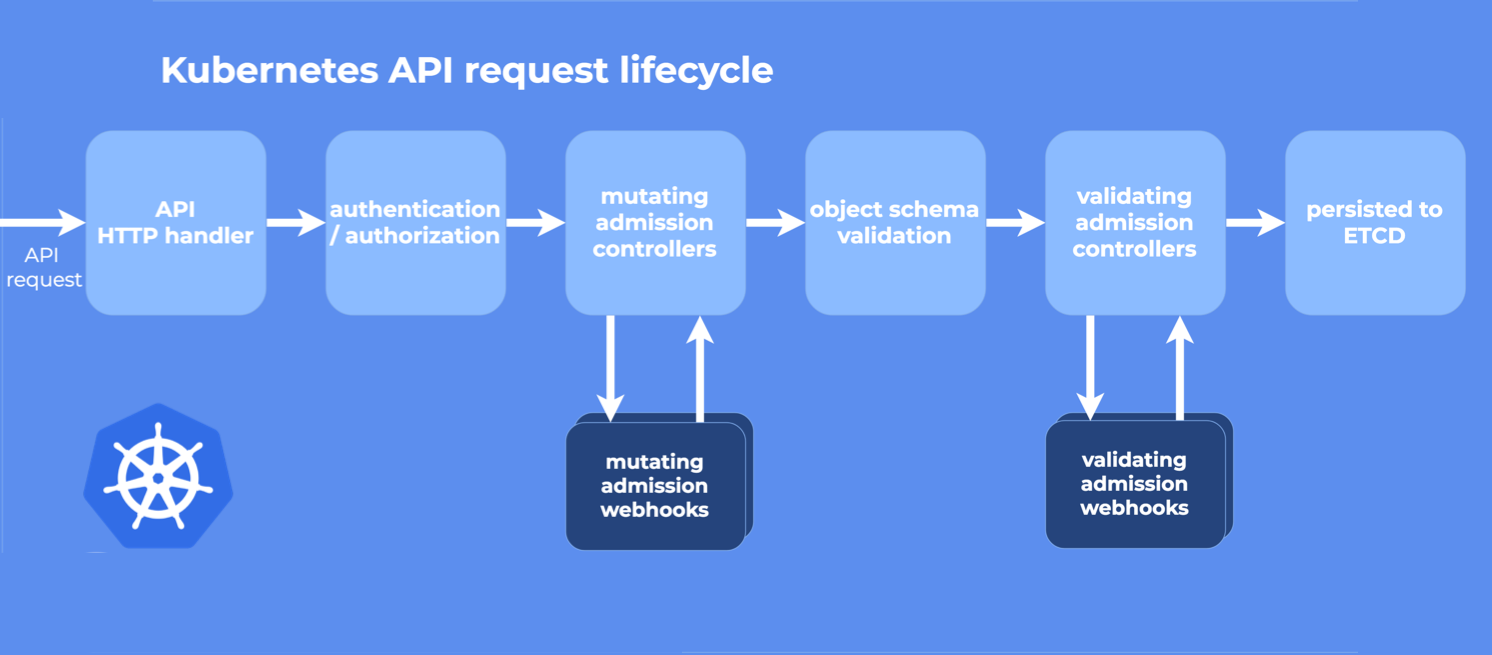
直到Spark3.1之前,Spark on Kubernetes仍然被官方定义为experimental,说明还并不成熟。和其他模式不同,没有常驻的节点资源,因此用户在使用时,对于依赖的管理、环境的配置、日志和监控都需要一些新的方式。目前在k8s上运行Spark,生产环境里使用的比例并不大。但kubernetes作为云原生的基石,Spark在k8s上运行已经是大势所趋。
Spark on Kubernetes官方文档提供的作业提交方式,是通过一个拥有本地Spark环境的client,执行bin/spark-submit来提交作业。这个client可以在k8s集群外也可以是k8s集群内的一个pod,通常会把它作为gateway单独用于作业提交。这种方式看起来和其他调度模式差别不大,只不过在参数中需要指定k8s的apiserver地址、镜像地址等一系列k8s独有的配置信息。
$ ps -ef UID PID PPID C STIME TTY STAT TIME CMD root 216 7 53 16:24 pts/0 Sl+ 0:03 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0/jre/bin/java -cp /opt /spark/conf/:/opt/spark/jars/* org.apache.spark.deploy.SparkSubmit --master k8s://https://{k8s-apiserver-host}:6443 --deploy-mode cluster --clas s org.apache.spark.examples.JavaWordCount --name spark-wordcount-example local:///opt/spark/examples/target/scala-2.11/jars/spark-example s_2.11-2.4.5.jar oss://{wordcount-file-oss-bucket}/
此时可以直接看到kubernetes集群中,pod已经启动了:
1 2 3 4 5
$ kubectl get pod NAME READY STATUS RESTARTS AGE spark-wordcount-example-1628927658927-driver 1/1 Running 0 7s spark-wordcount-example-1628927658927-exec-1 1/1 Running 0 2s spark-wordcount-example-1628927658927-exec-2 1/1 Running 0 2s
"main" #1 prio=5 os_prio=0 tid=0x00007f0e28051800 nid=0x8c waiting on condition [0x00007f0e2ee81000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000b2282088> (a java.util.concurrent.CountDownLatch$Sync) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836) at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:997) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1304) at java.util.concurrent.CountDownLatch.await(CountDownLatch.java:231) at org.apache.spark.deploy.k8s.submit.LoggingPodStatusWatcherImpl.awaitCompletion(LoggingPodStatusWatcher.scala:138) at org.apache.spark.deploy.k8s.submit.Client$$anonfun$run$2.apply(KubernetesClientApplication.scala:155) at org.apache.spark.deploy.k8s.submit.Client$$anonfun$run$2.apply(KubernetesClientApplication.scala:140) at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2545) at org.apache.spark.deploy.k8s.submit.Client.run(KubernetesClientApplication.scala:140) at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication$$anonfun$run$5.apply(KubernetesClientApplication.scala:250) at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication$$anonfun$run$5.apply(KubernetesClientApplication.scala:241) at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2545) at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication.run(KubernetesClientApplication.scala:241) at org.apache.spark.deploy.k8s.submit.KubernetesClientApplication.start(KubernetesClientApplication.scala:204) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:856) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:931) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:940) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
"main" #1 prio=5 os_prio=0 tid=0x00007f9258051800 nid=0x376 in Object.wait() [0x00007f925e88f000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000d5b23770> (a org.apache.spark.scheduler.TaskSchedulerImpl) at org.apache.spark.scheduler.TaskSchedulerImpl.waitBackendReady(TaskSchedulerImpl.scala:821) - locked <0x00000000d5b23770> (a org.apache.spark.scheduler.TaskSchedulerImpl) at org.apache.spark.scheduler.TaskSchedulerImpl.postStartHook(TaskSchedulerImpl.scala:196) at org.apache.spark.SparkContext.<init>(SparkContext.scala:562) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2537) - locked <0x00000000d5950988> (a java.lang.Object) at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:959) at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:950) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:950) - locked <0x00000000d59509e8> (a org.apache.spark.sql.SparkSession$) - locked <0x00000000d5950a08> (a org.apache.spark.sql.SparkSession$Builder) at org.apache.spark.examples.JavaWordCount.main(JavaWordCount.java:43) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:856) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:931) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:940) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)