
Hive Statistics介绍
Hive Metastore里除了保存元数据库表之外,还会保存statistics(统计信息)[1]。statistics记录了表或分区的大小、行数等信息,可以用于查询优化。Hive会在表、分区、字段级别记录各自的统计信息,主要包括:
例如我们新创建一张hive分区表,然后用hive插入一些数据,此时通过describe formatted语句可以看到表级别的statistics: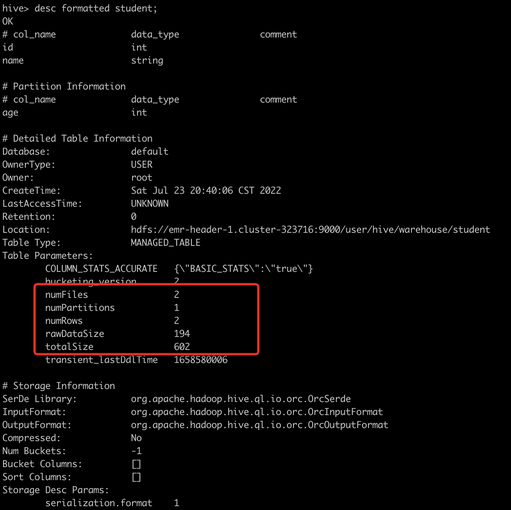
另外也可以指定partition查看某个分区的statistics: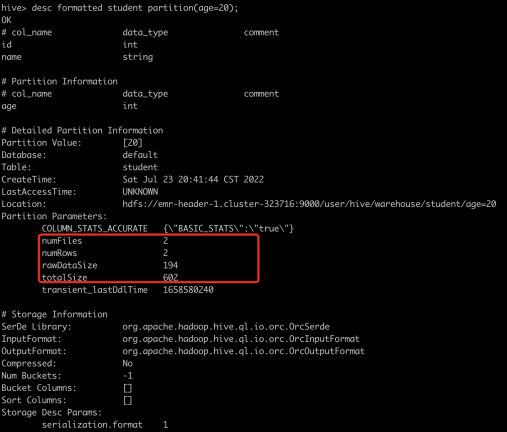
如果开启了hive.stats.column.autogather,或者我们再运行一下ANALYZE TABLE xxx COMPUTE STATISTICS FOR COLUMNS,那么还会创建出字段级别的statistics,可以通过describe formatted [table_name] [column_name]来查看每个字段的statistics,包括min/max等信息。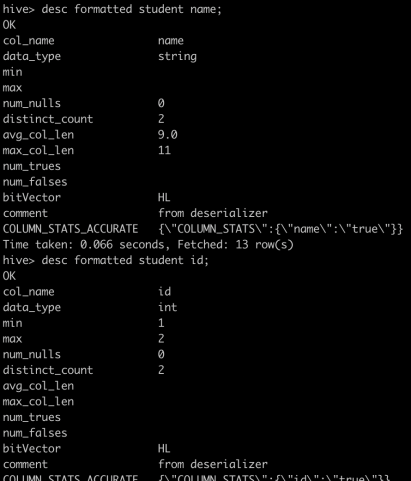
可以看到,Hive会尽可能地在每次变更数据时更新statistics以保证其准确性。当然用户也可以为了提高性能来关掉开关。Hive statistics会用于CBO(hive.cbo.enable)查询计划优化[2],来选择出代价最低的查询计划。另外,如果开启了hive.compute.query.using.stats(默认值关闭),诸如count(1)、min、max的查询会直接走Hive statistics快速返回结果,而不进行文件扫描。
Spark如何使用Hive Statistics
通常来说,Spark用户也会使用Hive Metastore来管理库表元数据,Spark本身也兼容Hive表的读写。不过Spark对于Hive Statistics的使用与Hive有所不同,首先来说Spark定义了自己的一组Param前缀(spark.sql.statistics.XXXX),并不依赖于Hive本身的statistics字段,Spark使用的statistics包括:
Spark自己定义了一套statistics key,这也意味着Spark引擎写入的statistics不会被其他引擎使用和共享,另外可以看出Spark对于statistics的写入相对于Hive要谨慎很多,在默认的配置下,Spark不会在数据写入时有效地更新statistics,意味着Hive Metastore里的统计信息不再能准确反映表的实际情况。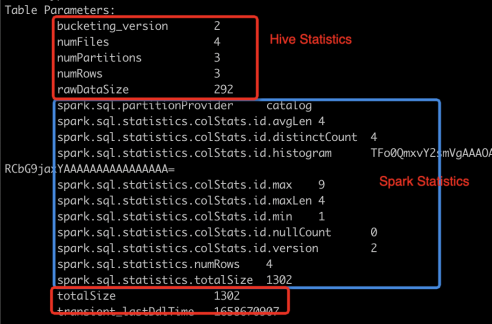
Spark Statistics的写入
上述表格已经列出了各个statistics key是在何时更新的,这里我们再详述一下。
表级别statistics
针对常规的SQL,Spark主要通过org.apache.spark.sql.execution.command.CommandUtils#updateTableStats这个方法来更新写入后的statistics,代码如下。代码的内容比较简单,仅当autoSizeUpdateEnabled开关打开,才会触发tableSize的计算,计算tableSize的原理为:如果是非分区表,递归list表存储路径下的所有文件,将每个文件size求和;如果是分区表,则默认会listPartitions先拿到所有分区的路径,然后每个分区大小并行计算。最终仅会更新表级别的spark.sql.statistics.totalSize属性。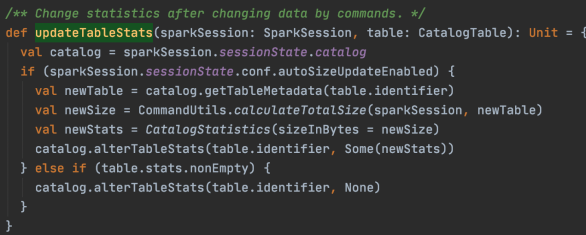
那这个方法什么时候会被触发调用呢,包括 _AlterTableAddPartition、CreateDataSourceTableAsSelect、AlterTableDropPartition、AlterTableSetLocation、LoadDataInto、TruncateTable_、以及两种Table的Insert(InsertIntoHadoopFsRelationCommand、InsertIntoHiveTable),都会调用CommandUtils.updateTableStats。也就是覆盖了所有数据更新或者表更新的场景,在开启开关后都会更新spark.sql.statistics.totalSize。
另外,要主动更新statistics还是要运行Analyze命令[3],对于 AnalyzeTable 命令,除了更新spark.sql.statistics.totalSize之外,也会根据参数noscan是否关闭来判断更新spark.sql.statistics.numRows,源码如下。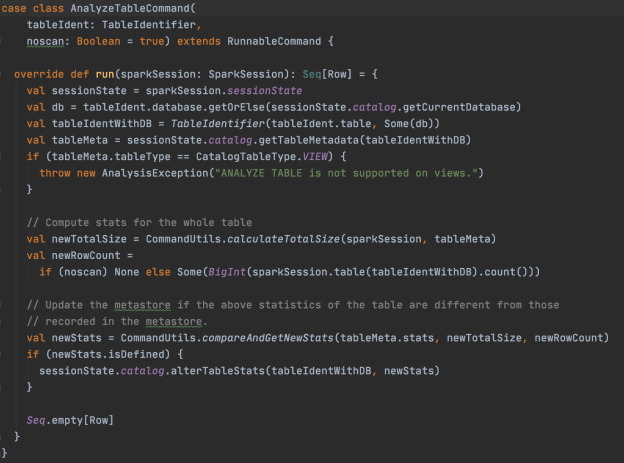
分区级别statistics
相比于表级别的statistics,分区级别statistics写入的场景更少了。即使你打开了spark.sql.statistics.size.autoUpdate.enabled这个开关,也不会在写入时自动更新任何分区级别statistics,因为这个开关只会写入表级别的statistics。包括当我们用spark新创建分区AlterTableAddPartition时,新分区的statistics也是空的。
不过除了Analyze命令以外,有一种情况,对于 ALTER TABLE … RECOVER PARTITIONS 语句,如果新创建了分区,则新分区会带上numFiles、totalSize这两个statistics。注意这里写入的statistics没有以spark.sql.statistics开头,而是写入了Hive格式的statistics,从代码注释看这样做的目的”This two fast stat could prevent Hive metastore to list the files again.”,也就是仅为了性能优化做的一次写入,毕竟这个命令在执行的时候已经扫描过一次分区目录了。
真正要更新spark的分区statistics,还是得运行 ANALYZE TABLE xxx PARTITION (xxxx = xxx) COMPUTE STATISTICS; 这个命令会更新分区statistics的两个key:spark.sql.statistics.totalSize、spark.sql.statistics.numRows。
字段级别statistics
Spark字段级别的statistics,只能通过 ANALYZE TABLE xxx COMPUTE STATISTICS FOR COLUMNS xxx; 语句来计算和写入。它记录了某个字段在整张表的min/max等统计信息,没有在分区维度进行统计。
Spark字段级别统计信息包括了avgLen、distinctCount、min、max、maxLen、nullCount以及histogram。前面几个统计值都好理解,histogram比较特殊,需要开启spark.sql.statistics.histogram.enabled之后再运行Analyze才可以生成。histogram将字段值的分布切分成n个百分比位(n=spark.sql.statistics.histogram.numBins,默认值254),每一段bin内部会统计min/max和distinct_count。
一份完整的Spark字段级统计信息如下图: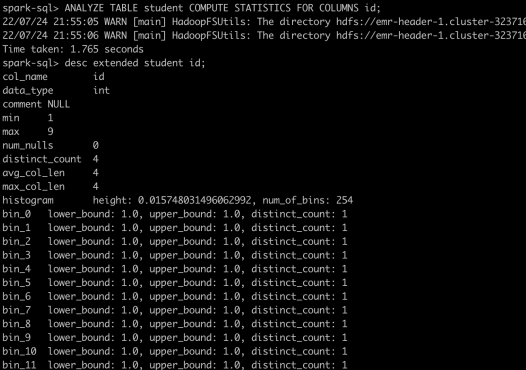
Spark可能也会更新Hive Stats
翻遍Spark源码,Spark更新的statistics都会以spark.sql.statistics开头,看似不会更新Hive格式的statistics。但实际情况下,Spark变更元数据时createTable/alterTable/addPartition会连接到Hive Metastore,此时在Hive Metastore内部依然会更新表和分区的statistics。这里更新的是Hive格式的stats:numFiles和totalSize。
那么问题就是Spark写入表的时候,是否会触发createTable/alterTable/addPartition这些ddl命令。类似于CTAS的语句,在创建元数据的同时进行插入肯定没问题会触发。如果只是普通的INSERT [OVERWRITE]命令,是否更新则要取决于Spark内部实现,Spark内部的插入有两种实现InsertIntoHadoopFsRelationCommand、InsertIntoHiveTable,分别对应Datasource表和Hive表。一个表的类型取决于Create table命令时候的语法[4]。另外如果是orc/parquet格式的Hive表,并且开启了spark.sql.hive.convertMetastoreParquet或spark.sql.hive.convertMetastoreOrc(默认是开启),则会做RelationConversion,实际上还是用InsertIntoHadoopFsRelationCommand来实现orc/parquet表的写入。如果是InsertIntoHiveTable命令,则会在写入非分区表时触发alterTable然后在Hive Metastore里计算statistics,同时也会更新transient_lastDdlTime。如果是InsertIntoHadoopFsRelationCommand命令,则不会触发alterTable,也不会计算statistics。
| 表类型 | 新增表/分区(CTAS、插入新分区) 是否更新Hive Stats |
普通INSERT插入表 是否更新表Hive Stats |
普通INSERT插入分区 是否更新分区Hive Stats |
|---|---|---|---|
| Datasource表 | 是 | 否 | 否 |
| Hive表 (除了orc/parquet) |
是 | 是 | 否 |
| Hive表 (orc/parquet) |
是 | 否 | 否 |
这里可以看出细节很多,也比较复杂,如果同一个表用不同引擎写入,或者用不同参数写入,可能行为都不一样。总体上看stats的写入在spark端来看是比较混乱的。
数据湖格式对statistics的使用
数据湖格式指的是delta、hudi、iceberg。数据湖格式通常不太依赖Hive Metastore的元数据,而是自己维护一份文件来记录表的元数据和统计信息。不同的格式对hive statistics的使用我做了一下测试,由于版本等原因,这里的结论仅做一个参考。
| 格式 | 写入数据是否更新statistics | Analyze是否更新statistics |
|---|---|---|
| delta | 会更新totalSize、numFiles | Spark3不支持Analyze Spark2的Analyze会更新spark.sql.statistics.numRows/spark.sql.statistics.totalSize |
| hudi | 会更新totalSize、numFiles | 会更新spark.sql.statistics.numRows 和 spark.sql.statistics.totalSize |
| iceberg | 会更新totalSize、numFiles、numRows | Spark3不支持Analyze Spark2不支持spark-sql |
总体来说,湖格式对Hive statistics的使用有几个特点
- 当数据写入时,默认会主动更新Hive statistics,无需开启其他参数(可能是由于触发metastore的alterTable更新,此处未验证)
- 写入的是Hive格式的statistics,而不是spark专用的spark.sql.statistics前缀的statistics
- 几乎不支持Analyze命令,因为Spark Datasource v2表暂不支持Analyze命令。而且即使运行了也是按照Spark的逻辑在执行,没有真正统计出湖格式的statistics。
- 真正的统计信息,通常都放在湖格式自己的元数据文件内
Spark Statistics的使用
在Spark内部实现里,会先从Hive Metastore里拿到的原始的statistics,构造出CatalogStatistics,随后在执行阶段会转换成Statistics。
Spark在构造CatalogStatistics时,无论是表级别还是分区级别的statistics,都是先读取Hive格式的statistics,再读取spark.sql.statistics前缀的statistics,如果存在则Spark的statistics优先覆盖Hive的statistics。读取字段级别stats则没有读hive的stats,而是只取了spark.sql.statistics.colStats开头的表级别stats。
最终在Spark的每个LogicalPlan的节点都会有一个名为stats的Statistics属性,表示了计划执行到此处预估的数据量org.apache.spark.sql.catalyst.plans.logical.statsEstimation.LogicalPlanStats#stats
那么这个plan里面的Statistics是怎么计算得来的,分几种情况:
- 不考虑cbo开启的情况下(默认cbo也是不开启的),估算stats的代码位于SizeInBytesOnlyStatsPlanVisitor。
- 执行计划树中,如果不是叶子节点,会根据操作类型从子节点的stats估算出本节点的stats,如Filter、Project、Aggregate等等,但是估算的方式简单且保守,Filter也没有真正减少stats,只能根据输出字段的不同来估算一下总大小的差异。可以认为经过若干算子之后,stats最终取值几乎还是表级别的totalSize值。
- 叶子节点,也就是真正的数据源,会根据不同表类型拿到stats信息。
- 对于Hive表(HiveTableRelation),会直接取CatalogStatistics,也就是原始的Hive Statistics的totalSize。

- 这里的tableMeta.stats不会是空,因为除了从Hive Metastore获取之外,在Analyzer阶段,Hive表还有一个专门的Rule:DetermineTableStats,会更新CatalogStatistics。如果开启了spark.sql.statistics.fallBackToHdfs(默认关闭)则会读取文件系统来计算totalSize,否则会取spark.sql.defaultSizeInBytes最大值。
- 另外我们本文以Spark2为例,Spark3的代码稍有不同但是基本一样。区别在于orc/parquet格式的Hive表,会用Datasource表的逻辑来取stats。
- 因此,对于Hive表,无论是否是分区表,stats取的都是Hive Metastore里表级别的totalSize,如果为空那么totalSize会取Long最大值。
- 对于Datasource表(LogicalRelation),会先取CatalogStatistics,取不到还会从datasource relation里面尝试拿totalSize。不同的数据源可以重写这个sizeInBytes,默认值是spark.sql.defaultSizeInBytes
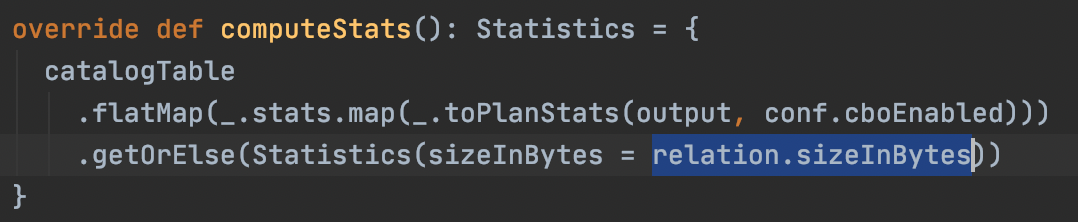 对于HadoopFsRelation类型的datasource,则还会尝试从FileIndex里面通过文件来统计totalSize,代码位于org.apache.spark.sql.execution.datasources.DataSource#resolveRelation。对于非分区表,会通过list所有文件拿到总大小;对于非分区表则不会,但是在optimize阶段有一个规则PruneFileSourcePartitions在一些情况下会更新分区表的stats的。
对于HadoopFsRelation类型的datasource,则还会尝试从FileIndex里面通过文件来统计totalSize,代码位于org.apache.spark.sql.execution.datasources.DataSource#resolveRelation。对于非分区表,会通过list所有文件拿到总大小;对于非分区表则不会,但是在optimize阶段有一个规则PruneFileSourcePartitions在一些情况下会更新分区表的stats的。 - 因此,对于Datasource表,也会优先读取Hive Metastore的stats,读取不到则非分区表的stats会从文件系统读取,分区表视情况而定。
- 对于Hive表(HiveTableRelation),会直接取CatalogStatistics,也就是原始的Hive Statistics的totalSize。
- 如果cbo开启,叶子节点的表stats读取逻辑和上述一致,不同的是一些算子Filter、Aggregate、Join之类的估算会更准确,比如Filter会拿子节点的rowCount、以及column的stats(min/max/distinctCount/histogram)来做估算。具体算法可以参考设计文档SPARK-16026[5]。
Join策略选择
得到查询计划里面的Statistics后,最重要的用处就是判断一张表是否可以做Broadcast Join。因为Broadcast Join可以把小表广播出去,性能要远优于Sort Merge Join。判断逻辑就是stats里的表大小,是否小于spark.sql.autoBroadcastJoinThreshold(默认10M,一般建议调大点)。
如上所述,执行计划中的Statistics会从Hive Metastore获取,尽管在有些场景下会通过list文件来兜底,但是并不能覆盖所有场景。一份准确的表级别stats可以避免小表被Sort Merge Join。例如:
1 | CREATE TABLE student (id INT, name STRING, age INT) STORED AS TEXTFILE; |

这是一个没有数据的空表,但仍然做了SortMergeJoin,如果有stats更新,才会走到BroadcastHashJoin。
不过Spark3开启AQE后,这个问题会好很多,AQE会自动Join策略调整DemoteBroadcastHashJoin,上述例子虽然explain的计划是SMJ但是执行过程中会变为BHJ。
cbo优化规则
cbo的开关(spark.sql.cbo.enabled)默认是关闭的,如果打开,一方面上述执行计划的Statistics会估算的更准确,另一方面也会增加一些执行计划的优化规则,主要就是CostBasedJoinReorder:
spark.sql.cbo.joinReorder.enabled开启后,会触发CostBasedJoinReorder这个Optimizer优化规则。这个规则会用来调整多个表连续Join时的Join顺序,通过这些表的stats和动态规划算法,优化成开销最小的Join顺序。
关于这个cbo规则的详细设计和算法,可以参考官方的设计文档 SPARK-16026[5]。
参考资料
[1] https://cwiki.apache.org/confluence/display/hive/statsdev
[2]https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
[3]https://spark.apache.org/docs/3.3.0/sql-ref-syntax-aux-analyze-table.html#content
[4]https://spark.apache.org/docs/latest/sql-ref-syntax-ddl-create-table.html
[5] https://issues.apache.org/jira/browse/SPARK-16026