
应用服务使用缓存是一个常见的策略。由于数据库持久化的特性,其读写QPS和性能相比于基于内存的Redis等缓存服务会相差很多。例如MySQL最简单的按主键查询数据至少需要几毫秒,而Redis正常一次GET查询只需要几百微秒。另外Redis的单机QPS相比MySQL也有明显优势,普通MySQL的QPS勉强过万,而Redis的QPS可以达到十万级别。
因此在应对大流量读或者性能敏感的场景,缓存就不得不考虑了。而一旦使用了缓存,就意味着缓存和数据库之间可能存在不一致,用户就有可能读到脏数据。有些业务场景对一致性不敏感,可以简单粗暴地使用缓存甚至做多级缓存。但在很多场景下,缓存不一致也会带来严重问题。虽然谈到缓存,大家会想到CAP定理,C和A不可兼得,但是我们还是有多种办法,尽可能保持缓存的一致性。下面就来讨论几种使用缓存的设计思路。
Cache-Aside模式
Cache-Aside (Lazy Loading) 模式是最常用的缓存模式:应用程序每次查询时先查询缓存,如果缓存不存在则查询数据库,并把读出来的数据写入缓存中。
在这个模式中,应用程序分别独立操作缓存和数据库,数据库和缓存之间没有交互。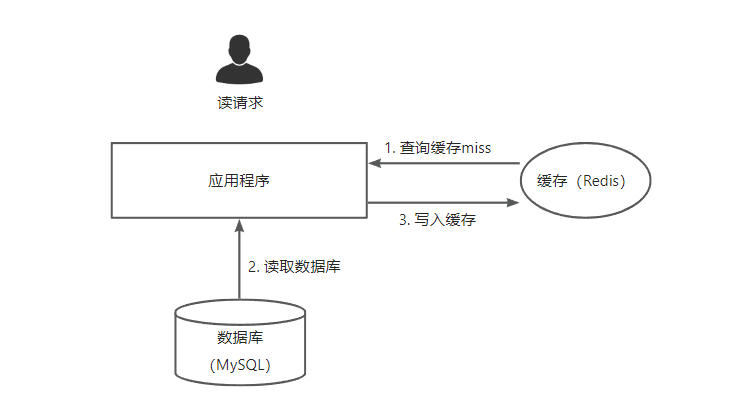
虽然Cache-Aside模式的读流程没有争议,但缓存的更新流程还是有不同的方案的。根据不同情况,可以按需选择不同的缓存更新策略:
写时更新缓存
写时更新缓存,适用于写入之后立即读的场景,不必担心第一次读取不命中缓存带来的性能损耗。我们再分成几种具体情况来分析:
- 先更新缓存,再更新数据库(不推荐)
这种方案应该直接否掉,因为相比于先更新数据库而言没有优势只有劣势。除了并发更新的问题之外,由于更新数据库耗时比更新缓存要慢很多,读请求读到脏数据的时间窗口就会变大。另外更新数据库失败的概率(唯一索引冲突、事务超时、事务回滚)要远高于缓存更新失败的概率,就更容易造成请求实际失败但是脏数据又写入了缓存的尴尬情况。 - 先更新数据库,再更新缓存(不推荐)
除非业务上可以保证肯定不会并发更新,不然这种方案不加锁也没有意义。因为更新数据库和缓存是分开的两个操作,在并发更新的情况下很可能因为顺序不一致带来缓存脏数据的问题。与其说更新一份脏数据,倒不如直接采用写时删缓存的方法,交给后面读的时候更新缓存。 - 加锁的情况下,先更新数据库,再更新缓存(推荐)
通过加分布式锁,或者数据库事务提交之前更新缓存,可以避免(2)中并发更新带来的缓存不一致问题。这样既可以保证缓存一致性,也可以避免写后第一次读取无法命中缓存的问题。而且一般的写流程本身就带数据库事务,增加一次缓存更新也不会带来多少性能损耗。
有些人不推荐这种方案,但是对于读多写少的场景而言,我认为是可以认真考虑这么做的。
但这些是建立在所有操作都成功的条件下的。如果出现一些异常情况,仍然是难以保证缓存一致性的。
- 如果更新缓存的操作失败,那么
- 可以重试几次,但是如果重试依然失败就只能忽略了
- 也可以直接让数据库事务回滚,但是会影响业务的可用性。另外如果缓存更新是超时,就说明有可能缓存其实更新成功了,那此时回滚数据库反而又带来了不一致
- 如果数据库事务提交失败,或者分布式锁超时,也是难以处理。不过这些概率都很低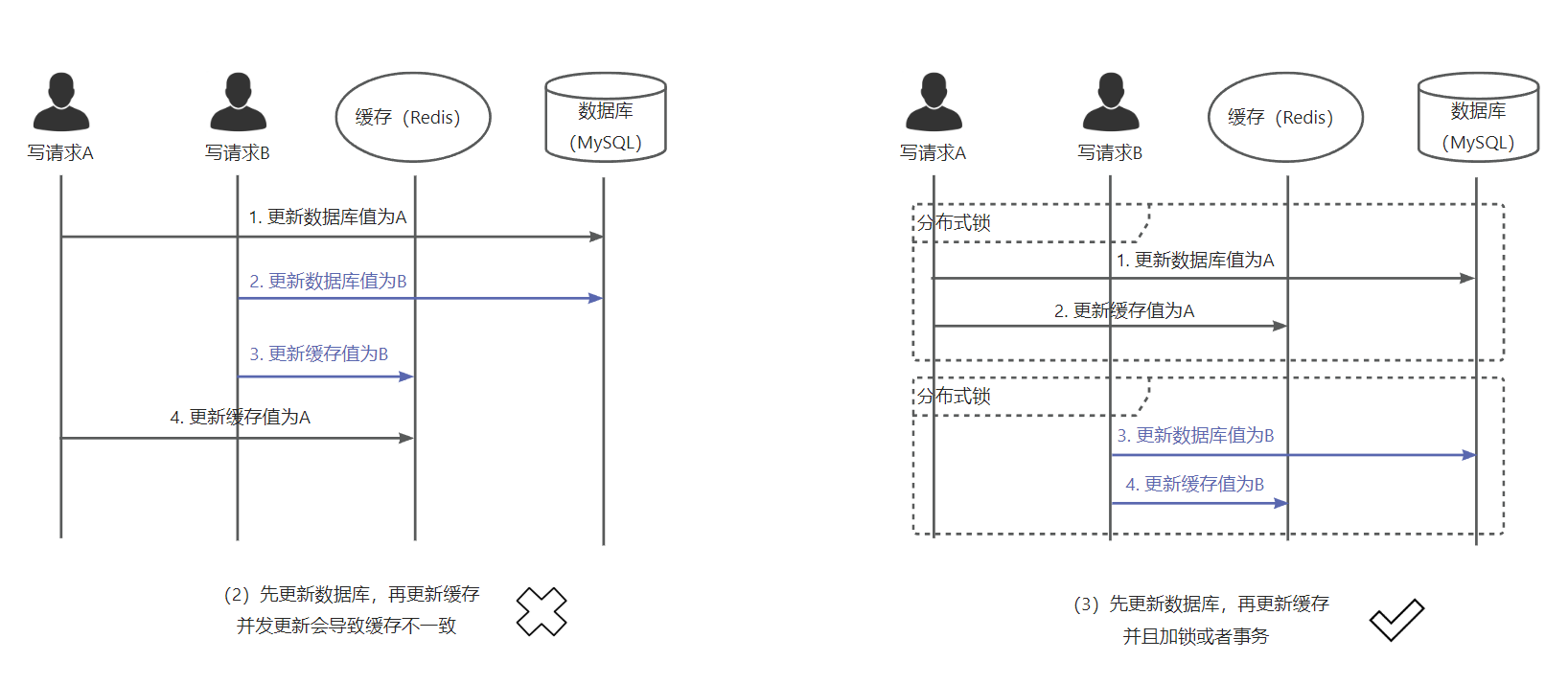
写时删缓存
相比于写时更新,写时删缓存是一种更常见的做法。删缓存可以完全避免更新缓存时序带来的问题。那么接下来就是先更新数据库还是先删缓存呢?
- 先删缓存再更新数据库(不推荐)
先删缓存这种方案并不合适。因为删缓存之后,如果刚好来了一次读请求,会把缓存值更新成旧值。就会造成缓存不一致。有些人建议这种方式搭配延迟双删使用,但即使用延迟双删我也建议先更新数据库,再删缓存,因为双删只是兜底补充方案。这种方式唯一我能想到的优点是,如果更新数据库之后应用直接挂掉,也许先删缓存会更保险一点,但既然这么谨慎了,不如采用删缓存-更新数据库-再删缓存的方式了。
- 先更新数据库,再删缓存(推荐)
这种做法是最推荐、最常用的做法。很多中文资料里,直接把这种做法定义成Cache-Aside模式本身了,不过我并没有找到严谨的出处。
对于写写并发,因为是删除缓存而非更新缓存,所以删除动作的时序并不会有影响。
对于读写并发,如果在更新数据库之后删除缓存之前,发生了读请求,确实会读到缓存的旧数据,但此时这个写请求并没有返回,因此可以认为读到旧数据也是符合预期的。另外,读请求在更新缓存时,极端情况下会有不一致,但这并不是这个写方案独有的问题,我会在下面的读流程注意事项里讨论。
如果再考虑到异常情况也是会不一致的,上面也讨论过如果删除缓存请求失败怎么办这类问题。
尽管不是完美的方案,但也是最值得考虑的方案了。相比于写时加锁更新缓存,唯一的缺点就是第一次读请求会变慢的问题了,这个问题在大多数场景下影响并不大。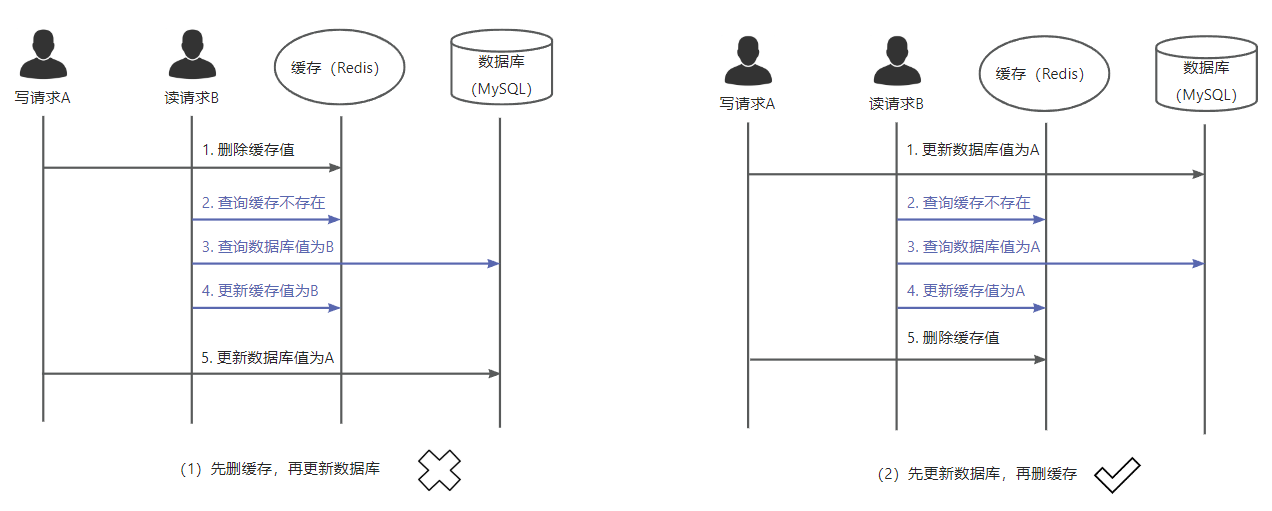
异步删缓存
异步删除缓存也是可以考虑的,而且可以搭配上面的方案同时使用,主要适合下面几种情况:
- 不想在写的流程里同步操作缓存,担心影响写的性能。但这会大大增加读到缓存脏数据的可能性。
- 作为兜底方案再删一次,以防写时操作缓存失败,或者因为并发原因缓存被写入了脏数据。
异步删缓存的几种方式:
- 消费MySQL binlog触发缓存更新
可以考虑使用Flink CDC或者消息队列,捕捉到数据库里某一条数据更新之后,就去删除对应的缓存值(至于要更新缓存的话就不建议了,时序很可能错乱)。对于一致性要求不高的场景,不失为一种方式,既不侵入应用代码逻辑,又能保证最终一致性。 - 延迟双删
考虑到写时删缓存因为各种原因可能出现不一致的情况,可以在第一次删缓存之后,再异步地隔几秒钟再删一次。尽管会稍微影响一些缓存命中率,但是亡羊补牢,总比缓存里长时间是脏数据要好。在生产实践中也是值得使用的方式。不过延迟双删也无法保证100%的最终一致,也只是在各种情况之中尽可能降低不一致的可能性。
读流程注意事项
如果一次读请求缓存未命中,查询过数据库之后,刚好有新数据写入,并且在读请求更新缓存之前完成了整个写入流程,如下图。此时无论采用哪种缓存更新策略,都会导致缓存写入错误的数据。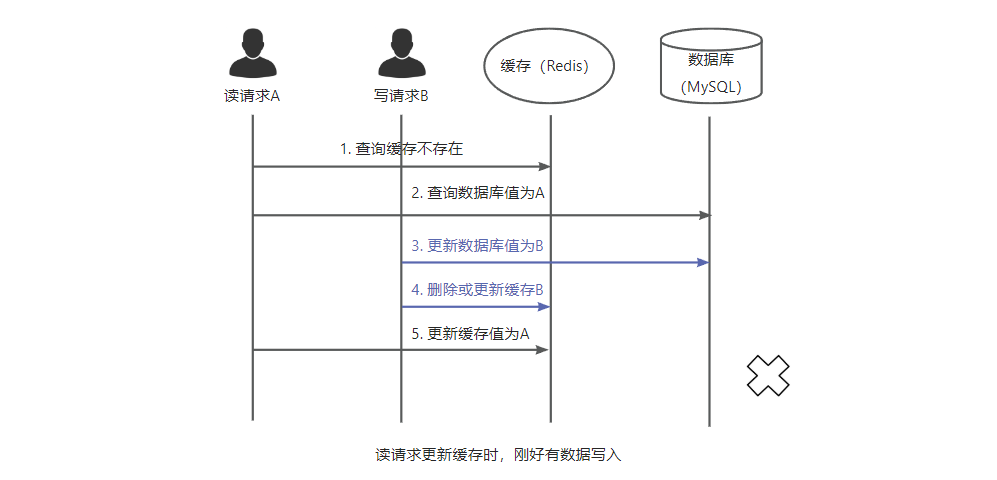
这种情况发生的概率很低,因为更新数据库耗时还是比较长的,这相当于读请求更新缓存之前卡住了很久。不过为了尽可能避免这种情况,也是有一些办法的:
- 读请求也加分布式锁,和写请求互斥。这是一个办法,但是给读也加锁实在不是一个好主意,我们使用缓存的本意就是提高读请求的QPS或者RT,一旦给读请求加锁,就严重损害了这个目的,就没有意义了。
- 读请求更新缓存值时(上图中步骤5),采用CAS原子操作。如果是写时更新缓存,我们可以认为读请求更新缓存时,缓存值一定是空的,否则就是中间有其他请求更新了数据,此时就应该放弃更新,读流程需要重试。如果是写时删缓存,仅凭借缓存值对比可能无法发现中间有过写入,这时可以再引入一个key,记录每个key的updateTime时间戳。采用CAS比对更新缓存虽然会带来复杂度,但不失为一种思路。
Read/Write-Through模式
Read/Write-Through模式中,应用程序只连接缓存,由缓存自己负责查询或者写入数据库。此时也可以把缓存服务当作一层抽象层,由一个缓存服务屏蔽缓存更新的细节。
读:优先从cache读,如果cache不存在则把数据load到cache中再返回
写:写cache,并同步或者异步更新到db
这种模式的好处在于应用程序不必再考虑复杂的缓存管理,但是缺点也是显而易见的:
- 缓存的读写接口不可能和OLTP数据库一样,使用数据库事务进行多表写入、复杂的SQL查询都是缓存服务难以处理的。
- 缓存一致性的挑战依然存在,仔细考虑上面Cache-Aside的读写并发的场景,依然需要逐一解决,只不过把难题交给了另一个服务而已。
实践中,很少有人会用这种方式做数据库缓存。Redis也提供了一种方案,可以搭配RedisGears来做write-behind, write-through, and read-through caching,个人认为实用性不高。
其实这种模式更适合在数据库内部来实现,例如MySQL Server本身就提供了Query Cache,这种才是真正对客户端透明的缓存。但是它是全局的缓存并不能根据业务场景来开关,而且对MySQL内存压力和性能都是挑战,生产环境通常也不会开启。
由于本文仅讨论给数据库做缓存的场景,并不是说Read/Write-Through这种模式不好。在其他场景中,例如Alluxio给对象存储做加速,以及需要近端缓存的场景,这种Read/Write-Through都是很常见的作法。
基于版本号做缓存
基于版本号做缓存,是非常实用并且能真正保证一致性的方案。适用于对一致性要求高的场景。
我们举一个实际的例子,电商系统里查询一个商品详情,包含了很多信息,通常要从数据库里查询多次,或者从外部服务请求多次,才能构造出最终结果返回。这种串行查询的做法,性能一定不会很好,我们可以在查询其他信息时采用多线程并发调用来适当优化,但是优化空间有限,而且每次请求的压力最终还是会打到数据库上。
此时可以给每个商品记录一个版本号,这个版本号可以是更新时间戳,或者在每次更新时+1,也可以是商品的Hash/MD5。然后把版本号作为key,完整的商品信息作为value存入缓存中。这样在下一次查询中,只需要select一下商品的版本号,就可以从缓存中拿到完整信息了,省去了其他复杂的关联查询。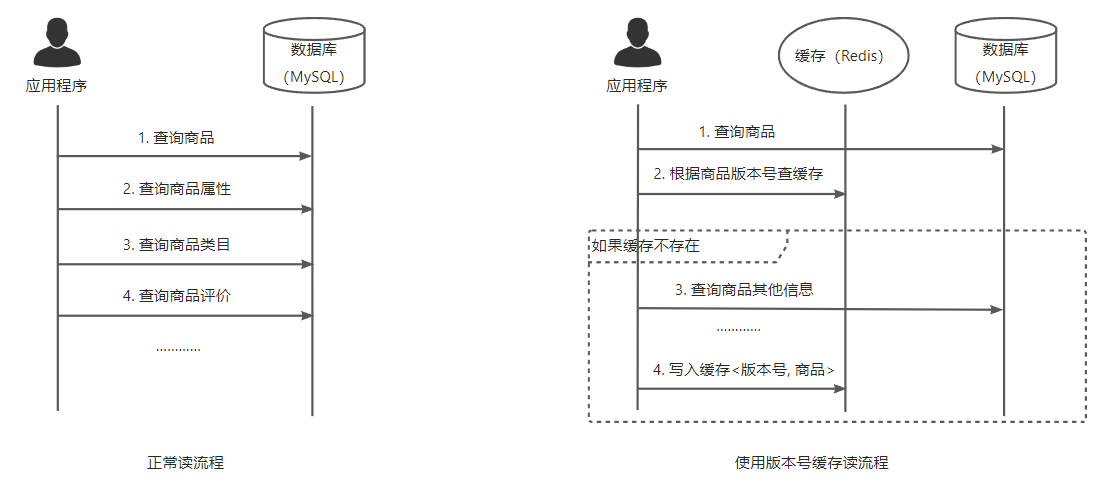
这种做法在其他场景也可以使用,例如对于结果体很大的查询,网络和序列化会耗时很多,此时可以用版本号缓存,快速查询一次服务端最新版本号,版本一致就可以直接返回。
只要把版本号的更新做到位,就不用担心缓存一致性问题。而且这种模式很灵活,缓存不仅可以放在服务端,放在客户端也可以。这种方案的缺点在于每次请求仍然要查询数据库,对高QPS并不友好,并且对业务逻辑有侵入,适用的场景有局限。
总结
首先,如果对缓存一致性要求高,并且每次读请求本身很耗时,优先考虑基于版本号做缓存。
如果难以实现版本号,或者对QPS和性能要求很高,考虑使用常见的Cache-Aside模式来实现缓存。此时必须认识到,在业务上必须接受缓存短暂时间的不一致。具体做法来说,优先考虑先更新数据库,再删缓存;如果看重第一次查询的缓存命中率,也可以加锁的情况下先更新数据库,再更新缓存。如果还想进一步降低缓存不一致的概率,还要考虑读流程并发更新缓存的问题,但通常来说没必要。
其实大多数需要使用缓存的场景,对一致性要求不会太高。尽管本文分析了各种复杂的缓存更新流程,真正落地还是需要简单有效,适合自己业务场景的方案才是最好的。