Spark的RDD分区,决定了每个Stage的Task任务切分,也是作业调优的重要因素。本文针对RDD的分区数是如何计算的,做一些简单的分析。
首先强调一下,这里讨论的分区(partition),都是RDD的概念,和表的分区是两回事,不要混淆。
一般原则
同一个Stage中,一般来说,每个RDD分区数=父RDD的分区数,但是有几种情况RDD分区会发生变化:coalesce transformation会减少RDD的分区,union transformation会增加RDD的分区(求和),cartesian也会增加RDD的分区(乘积)。接下来我们重点讨论下Stage中首个RDD分区由什么决定的。
来自文件输入的分区
对于没有父依赖的RDD来说,一般都是从文件读取的,从文件读取的分区划分根据不同的创建方式也有所区别:
使用sparkContext.textFile创建
如果文件使用sparkContext直接读取,我们以文本格式TextInputFormat为例,具体从源码来看: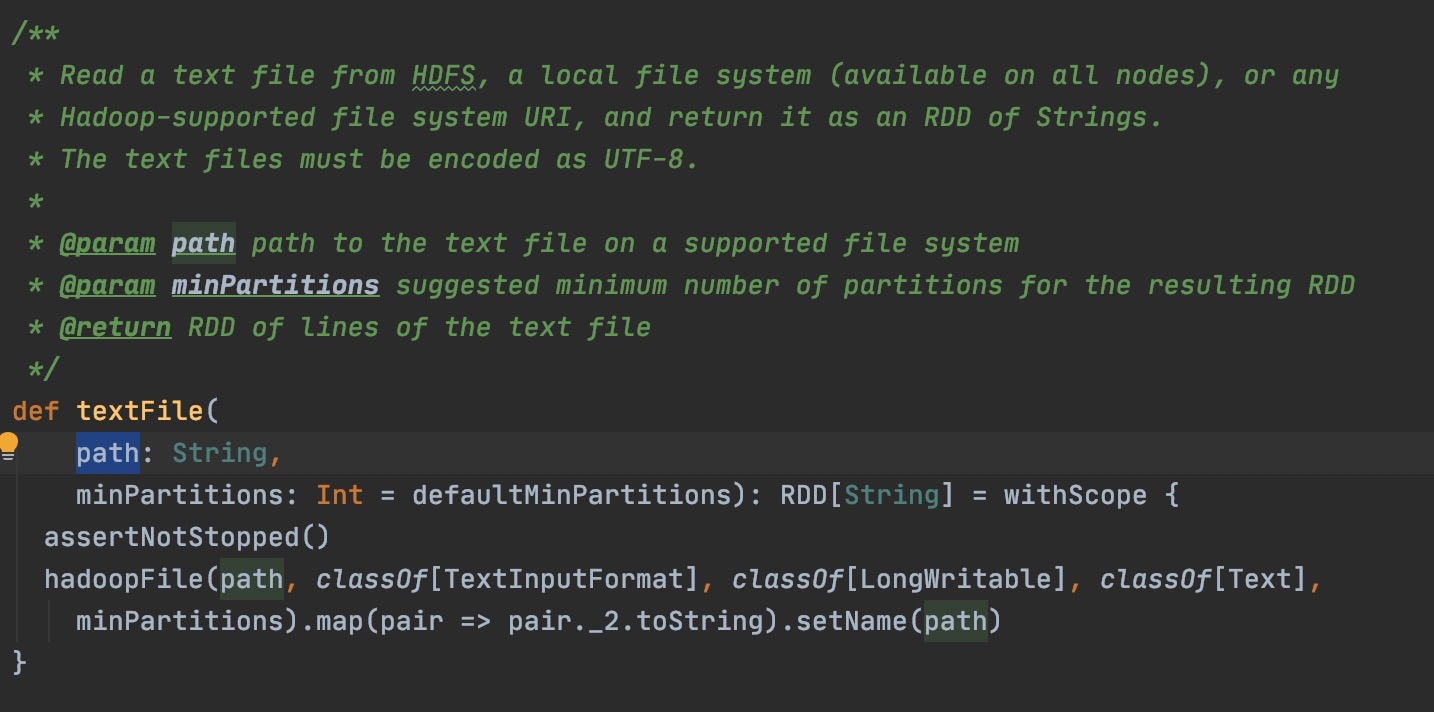
使用sparkContext.textFile来创建RDD,实际会创建一个HadoopRDD,然后做一次map产生MapPartitionsRDD。那最终这个RDD的分区其实是由最初的HadoopRDD决定的,分区逻辑主要在org.apache.hadoop.mapred.InputFormat#getSplits这个方法里。在我们这个场景下,实现类是org.apache.hadoop.mapred.FileInputFormat,getSplits返回的是具体的文件分区。
getSplits的实现逻辑,先从文件路径path拿到所有file,然后每个file,依据splitSize切分为多个split,每个split都会作为分区返回。splitSize取决于Min(goalSize, blockSize),其中blockSize取决于文件系统,一般是128M,goalSize=文件总Bytes大小 / numSplits,numSplits可以认为几乎永远等于2。
简单的说,对于小文件(小于128M),数量>=2的情况,可以认为是1个文件1个分区;对于大文件(大于128M),会根据blockSize把每个文件切分成多块,每个块都是一个分区。
使用spark.read.textFile创建
还有一种可能是通过spark.read.textFile来创建DataFrame/DataSet,这种创建出来的是FileScanRDD,这种方式更为常见,通过SparkSQL执行查询时,绝大部分表也是用这种方式来读文件的。其划分partition的源码在org.apache.spark.sql.execution.FileSourceScanExec#createNonBucketedReadRDD,计算分区的方式也是先根据splitSize切分文件,然后把切分后的文件分组形成partition。
先看切分文件方式:splitSize=Math.min(spark.sql.files.maxPartitionBytes, Math.max(spark.sql.files.openCostInBytes, bytesPerCore)) ,其中openCostInBytes默认4M,bytesPerCore=(文件总Bytes大小+openCostInBytes*文件数) / minPartitionNum,minPartitionNum优先取spark.sql.files.minPartitionNum的值,取不到则会取spark.default.parallelism,其中spark.default.parallelism是并行度关键参数,默认值是总cores。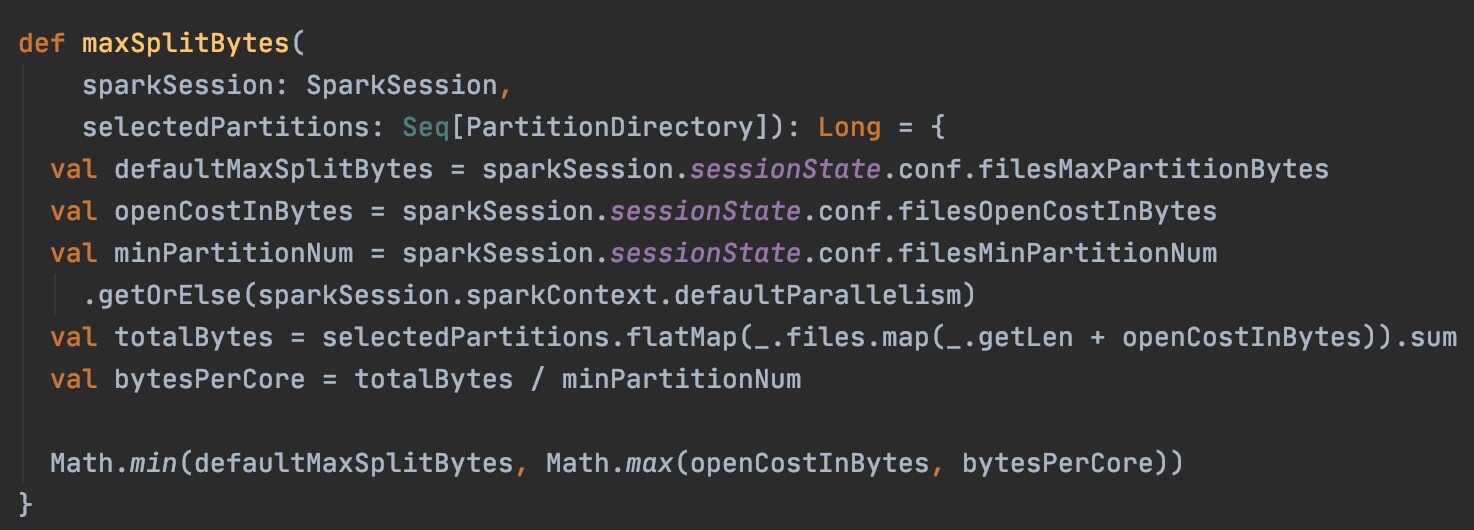
切分好文件之后,会把小文件或者切分的碎片做合并,最终形成分区。合并可以认为是尽量保障每个分区的大小能约等于splitSize大小,并且在其中考虑了openCostInBytes作为小文件的读取性能损失,让每个分区读取数据的cost尽量相同。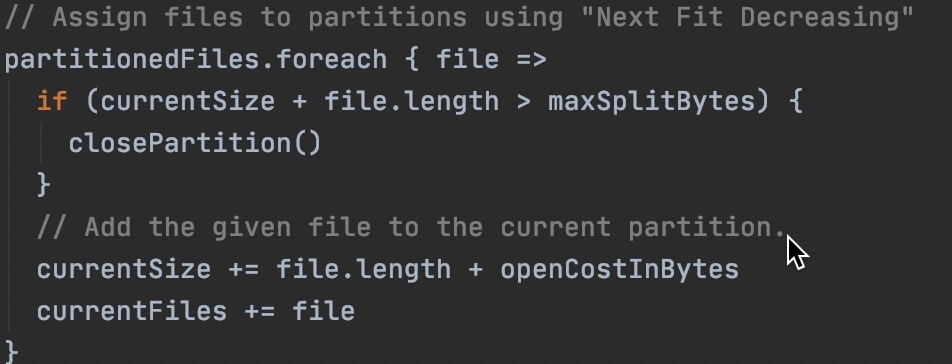
总结,简单的说
- 如果cores或并行度不大,但文件总大小又很大(或者小文件很多),平均每个core分派到的读取大小超过了128M,那么可以认为每个RDD分区按128M大小切分,分区数就取决于总大小/128M。
- 如果cores或并行度足够,文件总大小又比较小,平均每个core分派到的读取大小小于4M,会以openCostInBytes(默认4M)为1个Split来切分文件,每个Split代表一个分区。分区数就取决于总大小/4M。
- 如果介于上述两种情况之间,spark会尽量让分区数和cores并行度相等,每个分区读取的文件大小尽量相等。
举个例子来看:
我们准备了一个路径,存放了4个文件,每个文件都是10M大小,来跑Spark example里的wordCount。这个example是通过spark.read.textFile.javaRDD创建的RDD,因此符合SparkSQL的情况。
- 如果executor总core=2,那么每个stage的task数=2,也意味着RDD分区数为2,这4个文件中每2个文件代表1个RDD分区。
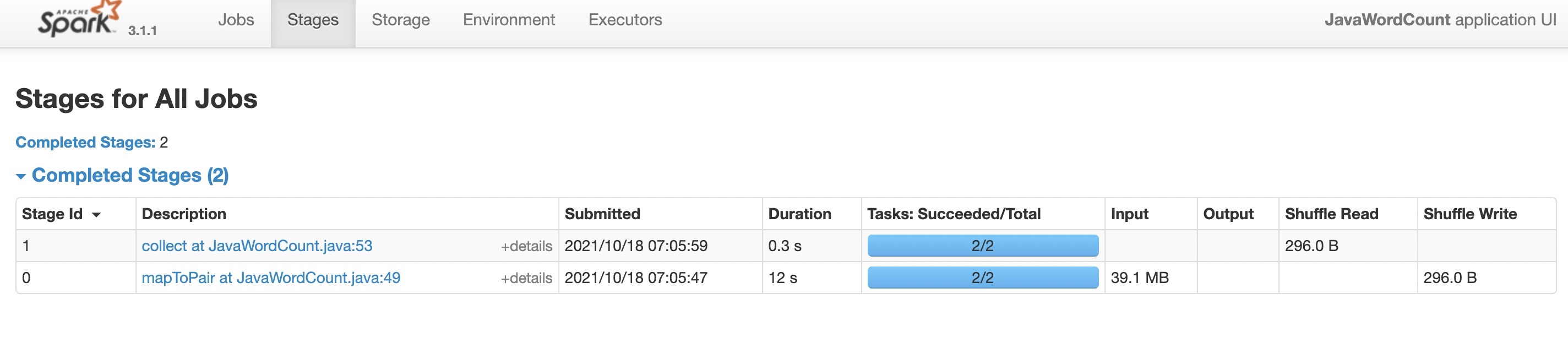
- 如果executor总core=1,会看到RDD分区数也是2,这是因为spark的并行度通过math.max(totalCoreCount.get(), 2)计算的,不会小于2。
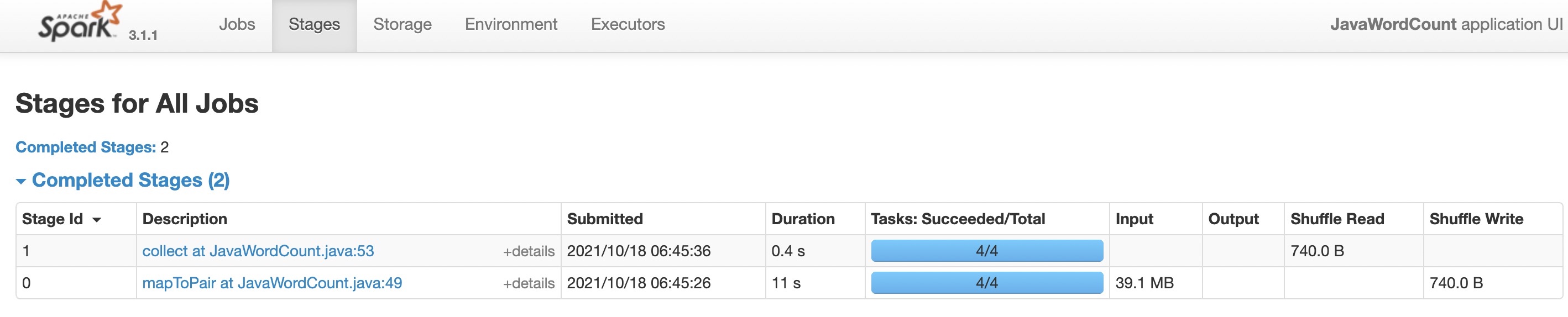
- 如果executor总core=3,会看到RDD分区数变成了4,也就是每个文件一个分区。这是因为,按照上面的公式来计算,bytesPerCore=10M*4+4*4 / 3=18.6M,大于每个文件10M的大小所以不会做切分,而两个文件的大小20M又超过了18.6M,所以也不会做合并,最终分区数和文件数一致。
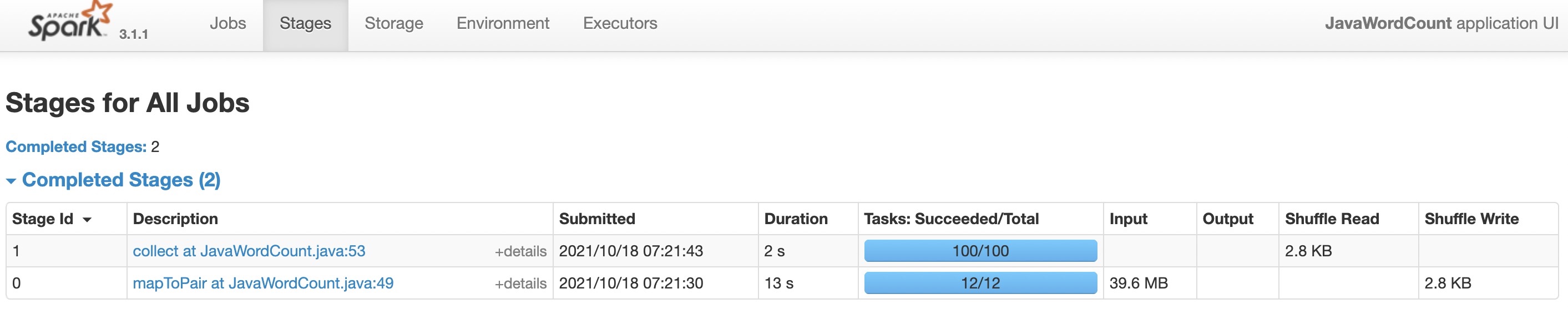
- 如果executor总core=100,或者设置spark.default.parallelism=100,会看到RDD分区数是12,之所以分区数最终没有那么多,是因为bytesPerCore=10M*4+4*4 / 100=0.56M,小于4M则会按4M来切分Split。4个文件每个文件10M,按4M切会切成3份,一共12个Split。
Shuffle后的分区
上面我们讨论了RDD分区根据父依赖或者文件输入的划分方式,还有一种情况是经过Shuffle,重新划分了Stage,数据也会重新分区,分区数也会变化。依然是两种情况:
使用RDD的Shuffle
如果直接使用RDD算子触发shuffle,例如repartition, coalesce, groupByKey, reduceByKey, cogroup, join等。其实这些算子在调用时是可以直接传入numPartitions或者分区器的,不过普遍大家并不会用到,所以我们都是按默认不传的情况来探讨。这些情况会创建ShuffledRDD,ShuffledRDD的分区来自于Partitioner,Spark默认的分区器和分区数的源码在org.apache.spark.Partitioner#defaultPartitioner: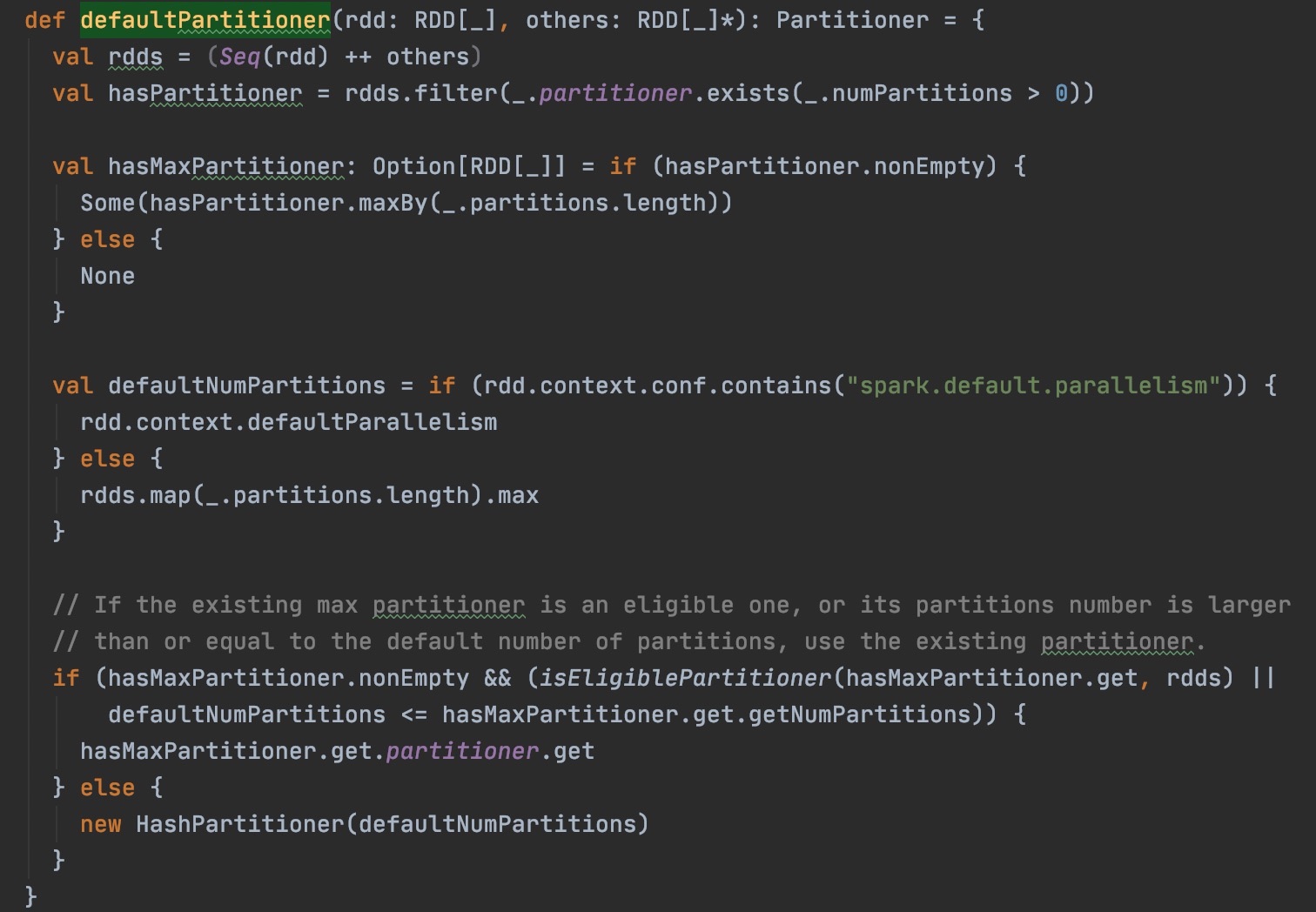
按照上面的注释,划分RDD的shuffle分区时,如果RDD本身没有设置分区器,分区数优先取spark.default.parallelism,未设置的话取上游RDD分区最大值(这里的上游RDD指的是参与shuffle的RDD,不是所有父RDD,例如join就是2个上游RDD)。如果有分区器,会取上游RDD分区和defaultParallelism的最大值。
If spark.default.parallelism is set, we’ll use the value of SparkContext defaultParallelism as the default partitions number, otherwise we’ll use the max number of upstream partitions.
When available, we choose the partitioner from RDDs with maximum number of partitions. If this partitioner is eligible (number of partitions within an order of maximum number of partitions in RDDs), or has partition number higher than or equal to default partitions number - we use this partitioner.
Otherwise, we’ll use a new HashPartitioner with the default partitions number.
Unless spark.default.parallelism is set, the number of partitions will be the same as the number of partitions in the largest upstream RDD, as this should be least likely to cause out-of-memory errors.
可以从上文wordCount的例子来看,从文件创建的RDD没有分区器,所以默认Shuffle前后分区数是不变的;在第四种情况如果手动设置了并行度spark.default.parallelism,则Shuffle分区数会和并行度数量一致。
下面是另一个没有设置过并行度的一个简单的例子,Shuffle前后的分区数没有变化。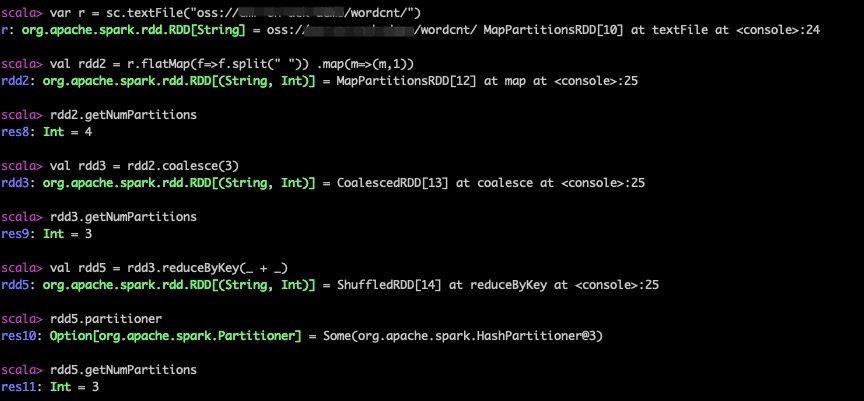
使用Spark SQL的Shuffle
如果直接使用SQL或者DataFrame/DataSet API做shuffle,包括join, distinct, groupBy, orderBy等等,shuffle分区的划分方式和RDD的方式又有所不同:这里涉及到一个常见的调优参数spark.sql.shuffle.partitions控制,默认值是200。shuffle后的分区数就等于这个参数的值。
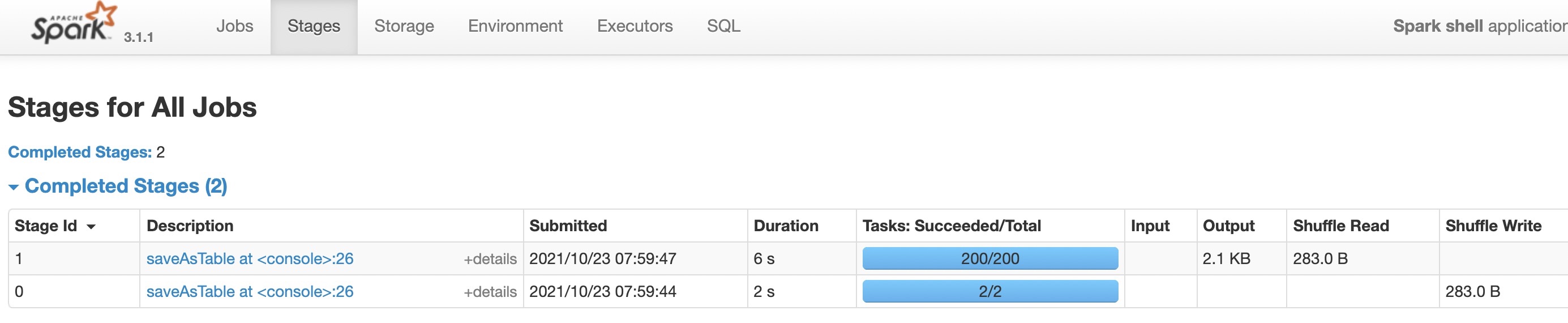
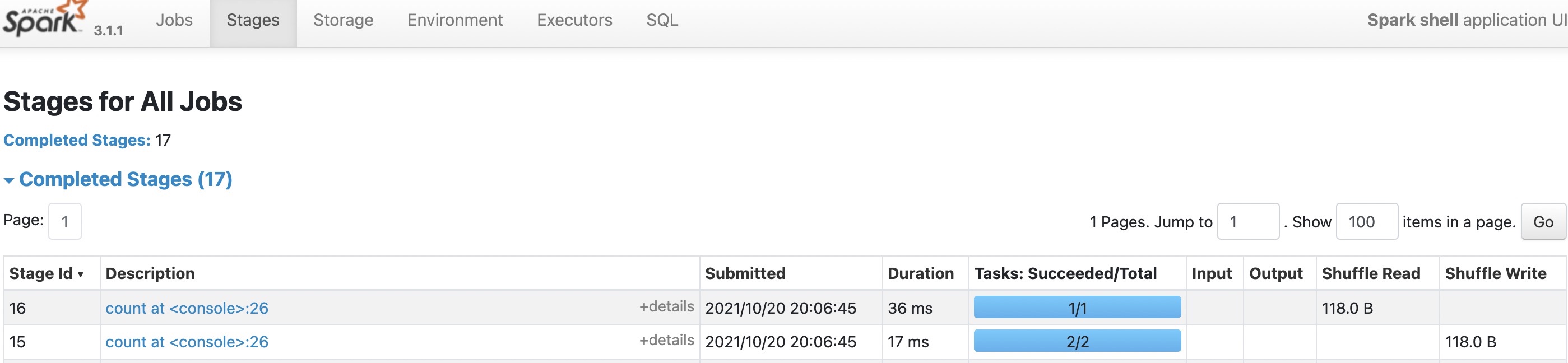
例如下方,一个简单的shuffle,即使只有几条数据,也需要200个partition,最终生成200个task。
大部分情况下,shuffle partition都遵循这个配置。当然这个配置项也不绝对,如果使用了BroadcastHashJoin,shuffle分区数会等于大表的分区数(待验证);或者进行了无条件的聚合操作,shuffle分区数会等于1。例如下面这个count操作,shuffle分区就等于1:
另外,Spark3之后的AQE,已经可以动态的对分区进行合并,开启之后(Spark3.2开始默认开启),shuffle分区会根据分区容量自动合并,也就不太遵循上面参数了。如下同样的例子,开启分区合并后,分区数已经变成了2:
向文件输出的分区
文件输出的算子(如saveAsTextFile),不会重新创建新的RDD,也不会重新划分stage,因此输出的分区遵循原本RDD的分区。这里主要提醒的是,输出的文件数目,就等于原本RDD的非空的分区数目。
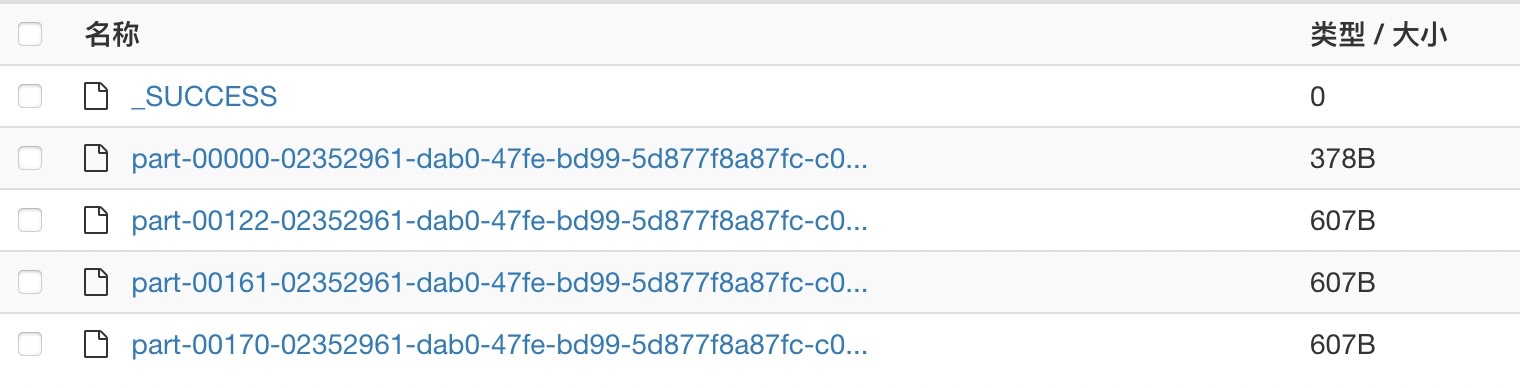
举个例子,我们读取文件,再repartition到12个分区,输出的文件个数,就等于repartition后的分区数12。
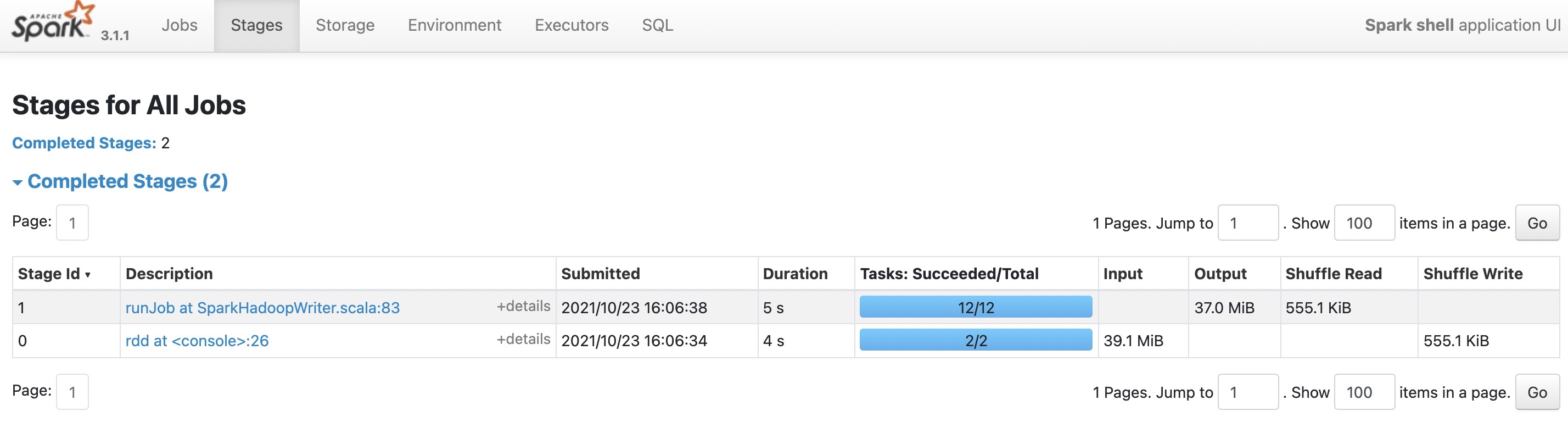
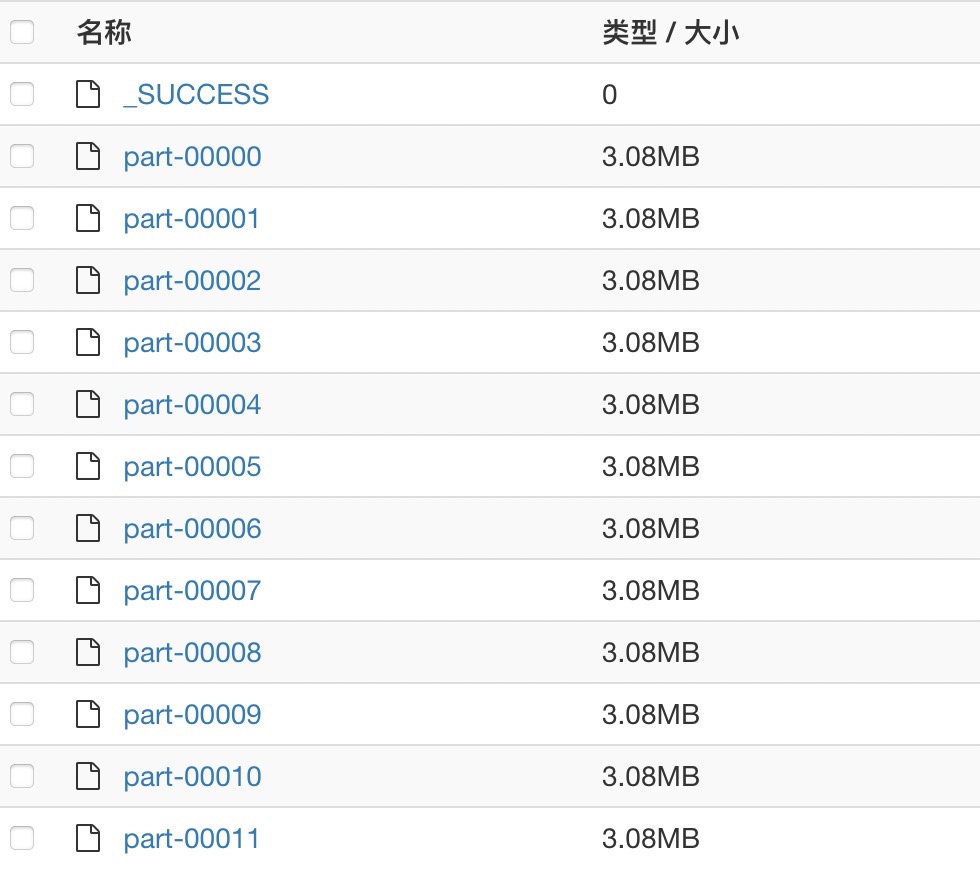
当然,如果是下面这种数据很少、分区很多的极端情况,即使分区数很多,没有数据的空分区也不会生成文件,最终写入的文件数就等于有数据的分区数目。